Clean Transcript (Quest)

OpenAI’s whisper macht großartige Arbeit beim Transkribieren, weit weit mehr, als wir uns erhofft hatten, und wesentlich präziser, als wir uns je erträumt hätten. Es kann aber natürlich nicht alles erfassen.
| Ist | Soll | Gibt-es-„Ist“-auch? |
|---|---|---|
| Cell-Run | Sell-Run | Möglich |
| Barlo | Barlow | Nein |
| Eltern | Add-On | Ja |
| Rate | Raid | Ja |
| DKB-Minus | DKP-Minus | Möglich |
Update & Tokens
Dabei muss sowohl das Vorkommen im Text, als auch in den Auszügen ge-up-dated werden. Man beachte auch dort die Tokens:
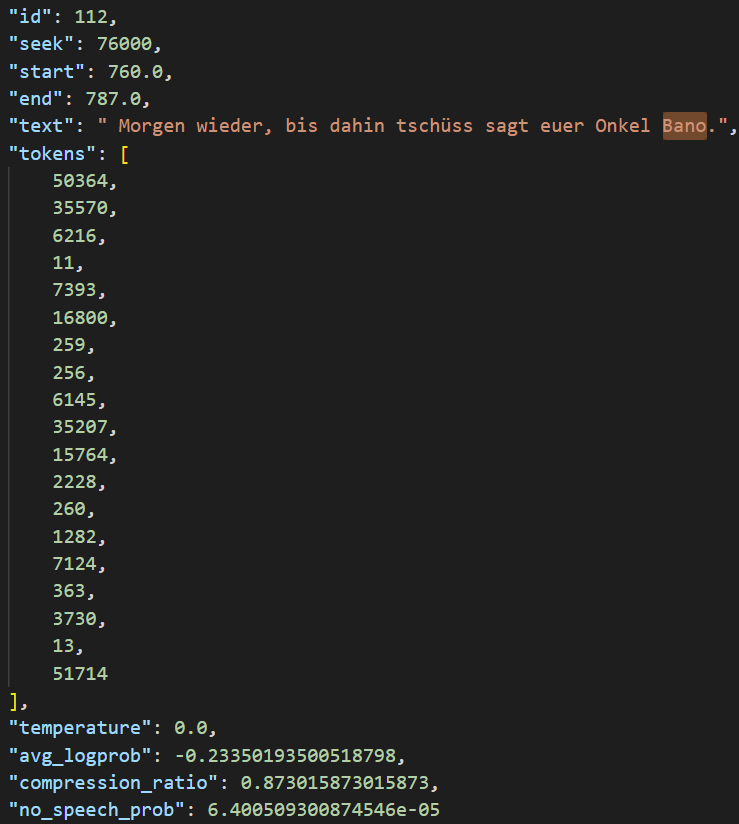
Statt der 3730 müsste hier der Token für „Barlow“ stehen – der dann noch zu finden ist.
Unklar ist derzeit, ob tokens einzigartig sind und über files hinweg bestehen.
Aktuelle Vermutung:
- Die Tokens stehen für Morpheme
- Pano, Bano, Barlo und Barlow hätten demnach alle den Token „3730“
- Unklar ist, ob z.B. „isst“ und „ist“ auch die gleichen Tokens haben
Lokal & Global
Ist all das berücksichtigt, sollten Lokale und Globale Dictionaries angelegt werden: aus „YuTup“ kann vermutlich immer „YouTube“ gemacht werden, aus „Barlo“ aber nicht immer „Barlow“, sondern vielleicht eher „Barlos“ oder was-auch-immer.
Pipeline
Ist dieser Schritt erfolgt, muss die Pipeline erneut ausgeführt werden, damit Wiki und Co aktualisiert werden.
Update: Quest abgeschlossen (2022-12-24)
Im Zuge des Abschluss der BMZ-Questreihe haben wir eine Pipeline integriert, die nach Whisper aufräumen kann – aktuell noch sehr manuell gestützt. Das Ergebnis ist auf Github zu sehen, visuell ansprechend jedoch diese Seite:

So sieht eine vollständig manuell korrigierte Folge aus – Respekt an Whisper. Kaum Fehler, jeder voll verständlich.
Wer möchte, kann nun weitere Folgen auf data.bnwiki.de korrigieren.
Oder direkt auf GitHub weitere Verbesserungen einbinden.
Die Pipeline steht, das System funktioniert, und bis wir auch die Tokens revolutionieren, gilt: Quest abgeschlossen!